Duplicate Line Remover & Analyzer
Clean up your text by removing, keeping, or analyzing duplicate lines with advanced options
What is the Duplicate Line Remover & Analyzer?
The Duplicate Line Remover & Analyzer is a comprehensive text processing tool for developers, data analysts, and content editors. It goes beyond simple duplicate removal to provide advanced filtering, analysis, and visualization of duplicate patterns. With customizable options, intelligent pattern detection, and detailed statistics, it helps you clean, organize, and understand text data with precision.
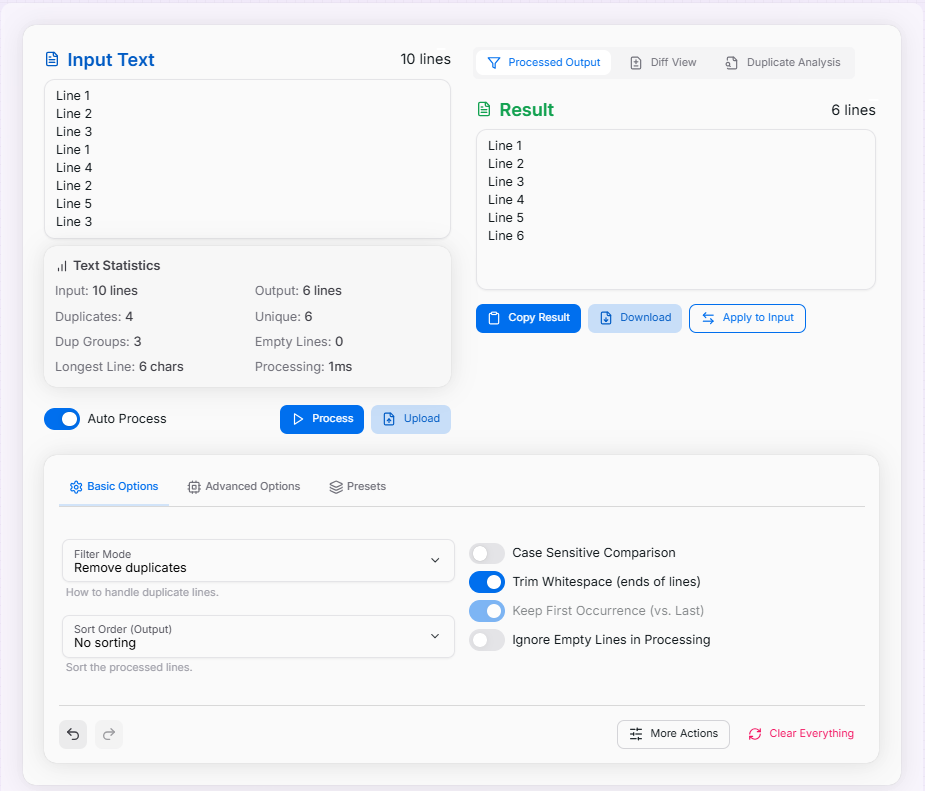
How to Use the Duplicate Line Remover & Analyzer?
- 1Input your text:
Enter, paste, upload a file, or use sample generators.
- 2Configure processing options:Basic Options:Filter mode, sort order, case sensitivity, whitespace.Advanced Options:Regex filtering, custom separators, line numbering.Presets:Apply pre-configured or custom settings.
- 3Select filter mode:
(Remove duplicates, Keep only duplicates, Highlight, Count, Mark first).
- 4Process your text:
Click "Process" or enable "Auto Process".
- 5Explore results:Processed Output:View filtered text.Diff View:Compare input and output.Duplicate Analysis:Details on duplicate patterns.
- 6Use additional tools:
Sorting, grouping, view statistics.
- 7Export or share:
Copy, download (text/JSON).
Processing Modes Explained
Remove Duplicates
Keeps only the first occurrence of each line, removing subsequent duplicates.
Keep Only Duplicates
Removes unique lines, keeping only those that appear multiple times.
Highlight Duplicates
Keeps all lines but visually marks duplicate occurrences.
Count Duplicates
Displays each unique line with its occurrence count, sorted by frequency.
Mark First Occurrences
Distinguishes between first occurrences and duplicates with different markers.
Sorting Options Explained
Sort A-Z (Ascending)
Arranges lines alphabetically from A to Z.
Sort Z-A (Descending)
Arranges lines in reverse alphabetical order (Z to A).
Length (Shortest First)
Arranges lines by character count, shortest first.
Length (Longest First)
Arranges lines by character count, longest first.
Natural Sort
Sorts text recognizing numbers, ordering them numerically (e.g., "Item 2" before "Item 10").
Key Features
Use Cases
Data Cleaning
Remove duplicates from datasets, CSVs, or database exports.
Code Maintenance
Clean duplicate imports, find redundant code blocks.
Log File Analysis
Extract unique errors, identify recurring patterns.
Content Management
Deduplicate email lists, remove redundant content.
Pattern Discovery
Analyze frequency patterns, discover common phrases.
Data Transformation
Process text in ETL workflows or transformation pipelines.
Advanced Tips
- Multi-Stage Processing: Chain operations (e.g., remove duplicates, then regex filter, then sort).
- Powerful Regex Filtering: Use regex like
^[A-Z].*\d+$for lines starting uppercase & ending with a number. - Specialized Presets: Create presets for specific data types (e.g., "CSV Header Check," "Code Cleanup").
- Insightful Duplicate Analysis: Use the analysis tab to find systemic issues in data collection or content creation.
- Large File Handling: For very large files, disable "Auto Process" and consider breaking them into smaller chunks.
Whether you're cleaning code, preparing datasets, or organizing content, our Duplicate Line Remover & Analyzer provides comprehensive tools for effective text duplication management. Start using it today to clean, organize, and gain insights from your text data with precision and efficiency.